The DDGemb prediction method
The DDGemb method is currently described in the following preprint article:
Savojardo, C, Manfredi, M, Martelli, PL, Casadio, R (2024) DDGemb: predicting protein stability change upon single- and multi-point variations with embeddings and deep learning bioRxiv 2024.09.05.611455
DDGemb exploits the power of ESM2 protein language model (Lin et al., 2023) for protein and variant representation in combination with a deep-learning architecture based on a Transformer encoder (Vaswani et al., 2017) to predict the ΔΔG for single- and multi-point variations.
The DDGemb architecture (Figure 1) comprises two components: i) the input encoding and ii) the ΔΔG prediction model.
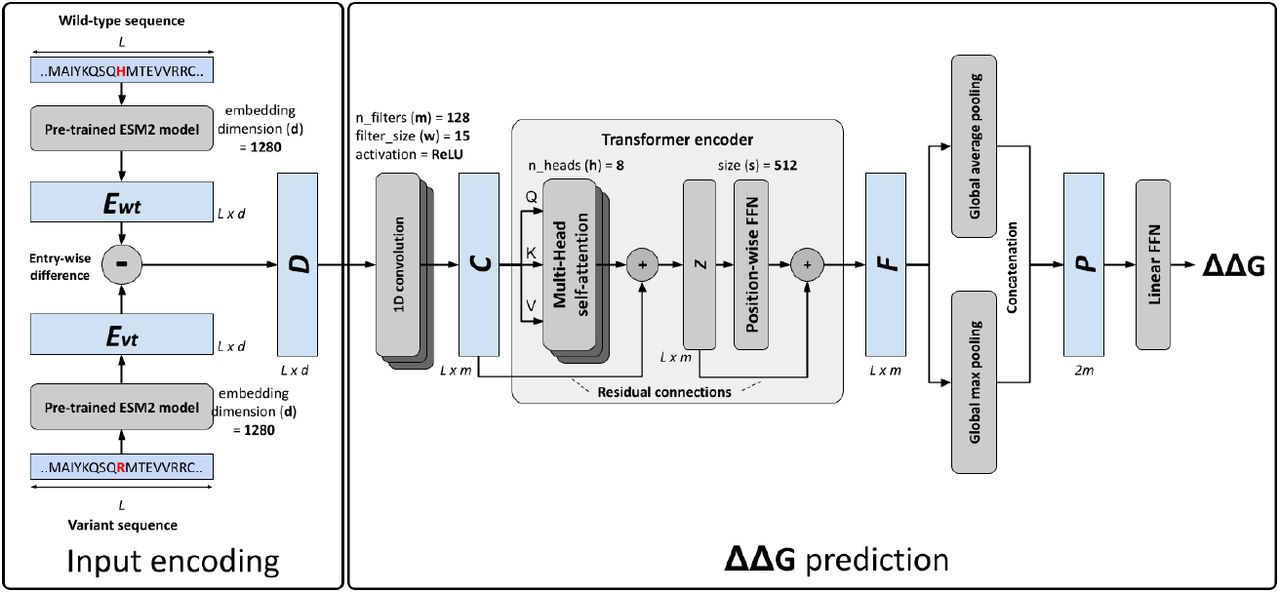
Figure 1. - DDGEmb deep-learning architecture
The input variation is firstly encoded as the difference between the ESM2 embeddings of wild-type and variant sequences. The variant sequence can be obtained either by a single- or a multi-point variation.
The difference matrix is then provided in input to a deep architecture including:
- A 1D convolutional layer including 128 filters of size 15 and ReLU activation.
- A Transformer encoder layer with 8 attention heads and hidden state of 512 units
- Two parallel global max and average poolin layers
- A final linear layer with a single output unit
The DDGemb has been trained using the S2450 datasets and tested on the S669 and the PTmul-NR datasets (see the Datasets section for deatils)
References
- Lin, Z. et al. (2023) Evolutionary-scale prediction of atomic-level protein structure with a language model. Science, 379, 1123–1130.
- Vaswani, A. et al. (2017) Attention Is All You Need. ArXiv170603762 Cs.